Function Summaries
Operators
Strictly speaking, operators in EViews are not functions as defined above, though they share a number of characteristics. As the name suggests, operators “operate” on data elements and return results.
• (“+”) Addition: adds two numeric values or concatenates strings.
• (“–”) Subtraction: subtracts the second numeric value from the first value.
• (“*”) Multiplication: multiplies two numeric values.
• (“/”) Division: divides the first numeric value by the second value.
• (“^”) Raise to Power: raises the first numeric value to the power of the second value.
• (“>”) Greater Than: returns 1 if the first value is greater than the second value and 0 otherwise.
• (“>=”) Greater Than or Equal To: returns 1 if the first value is greater than or equal to the second value and 0 otherwise.
• (“<”) Less Than: returns 1 if the first value is less than the second value and 0 otherwise.
• (“<=”) Less Than or Equal To: returns 1 if the first value is less than or equal to the second value and 0 otherwise.
• (“=”) Equal To: returns 1 if the first value is equal to the second value and 0 otherwise.
• (“<>”) Not Equal To: returns 1 if the first value is not equal to the second value and 0 otherwise
• (“and”) Logical And: returns 1 if both the first and the second condition are true, and 0 otherwise.
• (“or”) Logical Or: returns 1 if either the first or the second condition is true, and 0 otherwise.
There are a few key points to bear in mind:
• The precedence of evaluation is listed in
“Operators”. You can enforce order-of-evaluation using parentheses.
• When applied to series or alpha object expressions, the operations are performed for each observation in the current sample.
• When applied to matrix expressions the operations are performed on all of the observations. Note that the boolean comparisons will return 0 if any element of the test fails. For element tests, see
“Matrix Element Functions”.
Element Functions
Many EViews functions may be termed element functions since they takes arguments that correspond to numeric or alphanumeric scalar values, and return a single numeric or alphanumeric value.
EViews generalizes this basic behavior to arguments involving the elements of various data objects including series and alpha series, and the various matrix objects including vectors, matrices, and svectors.
Scalar Arguments
If the argument is a literal or scalar value, EViews will perform the computation and return a scalar value. To take a simple example, consider the log and @log functions, which both compute the natural logarithm of the numeric argument, and the @length and @left functions, which compute the length and return the left-most characters, respectively, of an alphanumeric (string) argument.
The commands,
= @log(3.2)
scalar s1= @log(1.2)
!s2 = log(s1)
all compute natural logarithms of the scalar numeric argument. The first command displays the results in the EViews status line, the second creates a scalar object S1, and the third assigns the value to a program replacement variable !S2.
Similarly, for the individual string arguments,
= @length("abcd")
string start = "When in the course"
string s4 = @left(start, 4)
%s4 = @left(start, 4)
the first command displays the number 4 in the status line, and the third and fourth lines both return the string “When”, assigning the result to a string object, and a replacement variable, respectively.
Workfile Data Arguments
If the argument is a series, alpha, or group, EViews evaluates an element function using the value for each observation in the current workfile sample, and returns a series or alpha depending on the function return type. In essence, the underlying function is evaluated repeatedly, in a loop over all observations in the sample.
The commands
wfcreate q 2001 2025
series y = rnd
smpl 2010 2020
series tr = @exp(y)
creates a quarterly workfile from 2001q1 to 2025q4, creates a random series Y, sets the sample to 2010q1 to 2020q4, and assigns the results from the @exp function to the new series TR over that subsample. Note that since the TR series is newly created, it will have NA values for all observations outside of 2010q1 to 2020q4.
Similarly, the commands
wfcreate q 2001 2025
alpha a = "<missing>"
smpl 2010 2020
alpha a = @chr(@trend)
initialize the alpha series A to contain the string value “<missing>” for all observations in the workfile, then sets the 2010q1 to 2020q4 subsample of A to contain the results from the @chr function evaluated at the @trend values.
Matrix Arguments
For matrix objects (broadly defined to include svectors) EViews evaluates the function for each element of the object and returns an object of the appropriate type and corresponding size.
Consider the commands
vector v1 = @fill(1, 2, 3)
vector vector logv1 = @log(v1)
which creates a 3-element vector V1 containing the values 1, 2, and 3, then employs the element function @log to create a 3-element vector LOGV1, with values 0, log(2), and log(3).
Further, the commands
matrix m1 = @mnrnd(3, 2)
matrix absm1 = @abs(m1)
fills a
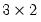
matrix M1 with standard normal random numbers, then uses the element function
@abs to create the
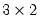
matrix LOGM1 containing the absolute values of the elements of M1 in corresponding positions. Note also that these two commands may be combined into the single line:
matrix absm1 = @abs(@mnrnd(3, 2))
Similarly, the commands
svector s1 = @sfill("apple", "pear", "orange")
vector lens1 = @length(s1)
sets up the svector by creating a 3-element vector containing the strings “apple”, “pear”, and “orange” and then uses the element function @length to create a 3-element vector LENS1 with values 5, 4, and 6.
Summary
Below we attempt to categorize the element functions into useful groupings. Naturally, the categorizations are not the only ones possible, but we have tried to provide groupings that will aid you in locating a function of interest. Because there are multiple ways to group the information, functions may appear in more than one category.
Numeric Constants
@pi Pi – ratio of a circle's circumference to its diameter
(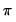 )
).
Basic Math Functions
@binomlog Natural logarithm of the binomial coefficient.
@ceil Smallest number greater than or equal to (with optional precision
).
@cloglog Complimentary log-log function.
@exp Exponential function.
exp Exponential function.
@expm1 Exponential function minus.
@fact Factorial function.
@factlog Natural logarithm of the factorial function.
@floor Largest number less than or equal to with optional precision.
@isna Test for missing value.
@log Natural logarithm function.
log Natural logarithm function.
@log10 Base-10 logarithm function.
@log1mexp Natural logarithm function of 1 minus exponential of argument.
@log1p Natural logarithm function of 1 plus argument.
@logx Arbitrary base logarithm functio
n.
@mod Floating point remainder.
@pow1pm1 Power function of 1 plus argument, minus 1.
@powm1 Power function, minus 1.
@round Nearest integer, or value at given precision.
Utility Functions
@between Dummy variable for value within range of values.
@iif Recode values by condition (conditional value).
@inlist Dummy variable for value in list.
@nan Recode missing values.
Trigonometric Functions
@acos Arc cosine (in radians).
@asin Arc sin (in radians).
@atan Arc tangent (in radians).
@cos Cosine of argument specified in radians.
@sin Sine function in radians.
@tan Tangent of argument specified in radians.
Statistical Distributions
The following functions provide access to the density or probability functions, cumulative distribution, quantile functions, and random number generators for a number of standard statistical distributions.
Most of the distributions support four different function types:
| |
Cumulative distribution (CDF) | @c |
Density or probability | @d |
Quantile (inverse CDF) | @q |
Random number generator | @r |
though some distributions support only a subset of the types. The listing below may also show related functions.
Note that the CDFs are assumed to be right-continuous:
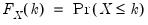
. The quantile functions
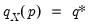
will return the smallest value
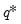
where the CDF evaluated at
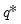
equals or exceeds the probability of interest:
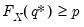
. The inequalities are only relevant for discrete distributions.
Many of the cumulative distribution functions take an optional argument at the end of the argument list. Non-zero values tell EViews to compute the upper tail of the CDF.
Discrete Distributions
Binomial
@cbinom Binomial cumulative probability function.
@dbinom Binomial probability function.
@qbinom Binomial distribution quantile.
@rbinom Binomial distribution random draw.
Negative Binomial
@cnegbin Negative binomial cumulative probability function.
@dnegbin Negative binomial probability function.
@qnegbin Negative binomial distribution quantile.
@rnegbin Negative binomial distribution random draw.
Poisson
@cpoisson Poisson cumulative probability function.
Continuous Distributions
Beta
@cbeta Beta cumulative distribution function.
@dbeta Beta distribution probability density.
@qbeta Beta distribution quantile.
@rbeta Beta distribution random draw.
Bivariate Normal
@cbvnorm Bivariate normal cumulative distribution function.
@dbvnorm Bivariate normal probability density function.
Chi-Square
@cchisq Chi-square cumulative distribution function.
@chisq Upper tail of the Chi-square cumulative distribution function.
@dchisq Chi-square probability density function.
@qchisq Chi-square distribution quantile.
@rchisq Chi-square distribution random draw.
Exponential
@cexp Exponential cumulative distribution function.
@dexp Exponential probability density function.
@qexp Exponential distribution quantile.
@rexp Exponential distribution random draw.
Extreme Value (Type I-minimum)
@cextreme Extreme value (Type I-minimum) cumulative distribution function.
@dextreme Extreme value (Type I-minimum) distribution function.
@qextreme Extreme value (Type I-minimum) distribution quantile.
@rextreme Extreme value (Type I-minimum) distribution random draw.
F-distribution
@cfdist F-distribution cumulative distribution function.
@dfdist F-distribution probability density function.
@fdist Upper tail of F-distribution.
@rfdist F-distribution random draw.
Gamma
@cgamma Gamma cumulative distribution function.
@dgamma Gamma probability density function.
@qgamma Gamma distribution quantile.
@rgamma Gamma distribution random draw.
Generalized Error
@cged Generalized error cumulative distribution function.
@dged Generalized error probability density function.
@qged Generalized error distribution quantile.
@rged Generalized error distribution random draw.
Inverse Wishart
@diwish Inverse Wishart probability density function.
@riwish Inverse Wishart random draws.
Laplace
@claplace Laplace cumulative distribution function.
@dlaplace Laplace probability density function.
Logistic
@clogistic Logistic cumulative distribution function.
Log Normal
@clognorm Log normal cumulative distribution function.
@dlognorm Log normal probability density function.
@rlognorm Log normal distribution random draw.
Multivariate Normal
@dmvnorm Multivariate normal probability density function.
@rmvnorm Multivariate normal random draws.
Normal
@cnorm Standard normal cumulative distribution function.
@dnorm Standard normal probability density function.
@logcnorm Natural logarithm of standard normal cumulative distribution.
@qnorm Standard normal distribution quantile.
@rnorm Standard normal distribution random draw.
Pareto
@cpareto Pareto cumulative distribution function.
@dpareto Pareto probability density function.
@rpareto Pareto distribution random draw.
t-distribution
@ctdist Student’s
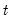
cumulative distribution function.
@dtdist Student’s
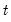
probability density function.
@tdist Tail probabilities of the Student’s
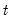
distribution.
@qtdist Student’s
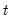
distribution quantile.
@rtdist Student’s
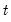
distribution random draw.
Uniform
@cunif Uniform cumulative distribution function.
@dunif Uniform probability density function.
@qunif Uniform distribution quantile.
@runif Uniform distribution random draw.
Weibull
@cweib Weibull cumulative distribution function.
@dweib Weibull probability density function.
@qweib Weibull distribution quantile.
@rweib Weibull distribution random draw.
Wishart
@dwish Wishart probably density function.
Financial Functions
The following functions perform calculations commonly employed in financial analysis.
@fv Future value of annuity payments and (optional) initial lump sum receipt.
@nper Number of periods for annuity to pay given present value.
@pv Present value of annuity receipts and (optional) final lump sum receipt.
@pmt Payment amount required for annuity to pay given present value.
@rate Discount rate required for annuity to yield given present value.
Special Functions
EViews provides a number of functions for evaluating special mathematical values such as Euler’s constant. For further details on special functions, see the extensive discussions in Temme (1996), Abramowitz and Stegun (1964), and Press, et al. (1992).
@beta Beta integral (Euler integral of the second kind).
@betaincder Derivative of the incomplete beta integral.
@betalog Natural logarithm of the beta integral.
@digamma First derivative of the natural log gamma function.
@erf Error function (Gauss error function).
@erfc Complementary (Gauss) error function.
@gamma (Complete) gamma function.
@gammader First derivative of the gamma function.
@gammalog Natural logarithm of the gamma function.
@psi First derivative of the natural log of the gamma function.
@trigamma Second derivative of the natural log gamma function.
References
Abramowitz, M. and I. A. Stegun (1964). Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables, New York: Dover Publications.
Press, W. H., S. A. Teukolsky, W. T. Vetterling, and B. P. Flannery (1992). Numerical Recipes in C, 2nd edition, Cambridge University Press.
Temme, Nico M. (1996). Special Functions: An Introduction to the Classical Functions of Mathematical Physics, New York: John Wiley & Sons.
Date Functions
@dateadd Date number after applying offset.
@datediff Difference between two date numbers.
@dateceil Last possible date in a time period.
@datefloor Earliest possible date in a time period.
@datenext First possible date in the next time period.
@datestr String representation of a date number.
@dateval Date number associated with a string representation of a date.
@localt Convert UTC (Coordinated Universal Time) to local time.
@makedate Convert numeric representation of a date to date number.
@now Current time date number.
@strnow String representation of the current date and time.
@time Current time as a string.
@tz Convert time in source time zone to destination time.
@tzlist Available time zone specifications.
String Functions
@asc ASCII value of character.
@chr ASCII value to string character.
@iif Recode values by condition (conditional value).
@inlist Dummy variable for value in list.
@instr Find position of substring in a string.
@isna Test for missing value.
@left Left-hand characters in a string.
@lower Lowercase representation of a string, or lower triangular matrix of a matrix.
@ltrim Trim left-whitespace from string.
@mid Substring in middle or from middle to end of string.
@nan Recode missing values.
@right Right substring of string.
@rinstr Find substring position in string.
@rtrim Trim right whitespace of string.
@str String representation of number.
@strdate String corresponding to the date of the observation.
@stripcommas Remove leading and trailing commas surrounding string.
@stripparens Remove paired leading and trailing parentheses surrounding string.
@stripquotes Remove paired double-quotation marks surrounding string.
@trim Trim left and right whitespace from string.
@upper Uppercase representation of a string; or upper triangular matrix of a matrix.
@val Number from a string.
@wcount Number of words in the string list.
@wcross String with words in first list crossed with second.
@wdelim Replace delimiters in string.
@wdrop Drop words from string list.
@wfind Find location of word (case-sensitive) in string list.
@wfname String containing name of current workfile.
@wfindnc Find location of word (not case-sensitive) in string list.
@wjoin Extract elements of an Svector to a string.
@wkeep Keep subset of words in string list.
@wleft Left-most words of string list.
@wmid Middle or middle to end words of a string list.
@wnotin Words not in a string list.
@word Single word from a string list.
@wordq Single word from a string list, preserving quotes.
@wread Read contents of text file into a string.
@wreplace Replace characters in each word in a string list.
@wrfind Find location of a word (case-sensitive) in a string list searching from end.
@wrfindnc Find location of a word (not case-sensitive) in a string list searching from end.
@wright Right-most words of a string list.
@wsort Sorted list of words in a string list.
@wsplit Create string vector from words in a string list.
@wunion Union of words in two string lists.
@wunique Remove duplicate words in string list.
Basic Statistics
EViews offers basic statistics functions which compute statistical summaries using the data in various EViews objects. Different functions support different types of source objects, with slight differences in how the function is computed depending on type of source.
Some statistics functions work with objects containing numeric data. Most of these functions will work with any object that contains numbers. You may, for example, compute the mean of series data using
@mean, the standard deviation of data in a vector using
@stdev, the trend coefficient from the regression of all of the data in a matrix on an intercept and trend using
@trendcoef, or the correlation matrix of data in a group of series using
@cor.
Other functions work with objects containing both numeric and string data. For example, you may use
@max to identify the last sorted value, or
@first to find the first non-missing or empty element of series, vector, coef, rowvector, alpha, or svector data.
Crucially, for basic statistics computed using series, alpha, or group data, most EViews functions will default to using data in the current workfile sample. You generally may provide an alternate sample specification, enclosed in double quotes, as the last argument in the function. For vector, svector, and matrix computation using functions, EViews will use all of the relevant data in the object.
Where summaries of matrices are allowed, EViews uses all of the elements of the matrix, by vectorizing the matrix before performing the computation. Special functions are available if you wish to perform individual computations for each of the columns of a matrix (
“Summary”).
For basic descriptive statistics, missing values, either in the form of numeric NAs or empty strings, are ignored.
Basic Statistics
@columns Number of columns in matrix object or group.
@cor Correlation of two vectors or series, or between the columns of a matrix or series in a group.
@cov Covariance (non-d.f.corrected) of two vectors or series, or between the columns of a matrix or series in a group.
@covp Covariance (non-d.f. corrected) of two vectors or series, or between the columns of a matrix or series in a group.
@covs Covariance (d.f. corrected) of two vectors or series, or between the columns of a matrix or series in a group.
@first The first non-missing value in the vector or series.
@ifirst Index of the first non-missing value in the vector or series.
@ilast Index of the last non-missing value in the vector or series.
@imax Index of maximum value.
@imaxes Indices of maximum value (multiple).
@imin Index of minimum value.
@imins Indices of minimum value (multiple).
@last The last non-missing value in the vector or series.
@mae Mean of absolute error (difference) between series.
@mape Mean absolute percentage error (difference) between series.
@maxes Maximum values (multiple).
@mins Minimum values (multiple).
@mse Mean of square error (difference) between series.
@nas Number of missing observations.
@norm Norm of series or matrix object.
@obs Number of observations.
@rmse Root of the mean of square error (difference) between series.
@smape Symmetric mean absolute percentage error (difference) between series.
@stdev Sample standard deviation (d.f. adjusted).
@stdevp Population standard deviation (no d.f. adjustment).
@stdevs Sample standard deviation (d.f. adjusted).
@stdize Standardized data (using sample standard deviation).
@stdizep Standardized data (using population standard deviation).
@sumsq Arithmetic sum of squares.
@theil Theil inequality coefficient (difference) between series.
@trendcoef Trend coefficient from detrending regression.
@uniquevals Vector or svector of unique values of object.
@var Population variance (no d.f. adjustment).
@varp Population variance (no d.f. adjustment).
@vars Sample variance (d.f. adjusted).
Series Utility
The following functions facilitate working with all of the observations of series and alpha data in a workfile.
@bridge Copy of series using the current or preceding non-missing value.
@cagr Compound annual growth rate of series (in decimal fraction).
d Difference (time-series) functions for series.
@demean Compute deviations from the mean of the data object.
@demeanby Compute deviations from the mean of the series by group.
@detrend Compute deviations from the trend of the data object.
dlog Difference functions for natural logarithm of a series.
@dupselem Identifier for the observation within the set of duplicates.
@dupsid Identifier for the duplicates group for the observation.
@dupsobs Number of observations in the corresponding duplicates group.
@eqna Test for equality of data objects, treating NAs and null strings as ordinary and not missing values.
@fracdiff Fractional difference of series data.
@inv Reciprocal function.
@lag n-th order lag function.
@neqna Inequality test (NAs and blanks treated as values, not missing values).
@pc One-period percentage change (in percent).
@pca One-period percentage change, annualized (in percent).
@pccagr Annualized growth rate (in percent).
@pch One-period percentage change (in decimal fraction).
@pcha One-period percentage change, annualized (in decimal fraction).
@pchy One-year percentage change (in decimal fraction).
@pcy One-year percentage change, (in percent).
@stdize Standardized data (using sample standard deviation).
@stdizep Standardized data (using population standard deviation).
@trendc Trend series using calendar dates.
Workfile Functions
EViews workfile functions provide information about each observation of a workfile based on the structure of the workfile.
These functions may be viewed in two ways:
• First, the workfile functions are virtual series available that can be used wherever a regular series may be used.
• Alternatively, the workfile functions may be thought of as special functions that depend on two implicit arguments: the workfile within which the function is being used, and the observation number within this workfile for which to return a value.
For example, the
@after function, which takes a single string date argument, may be thought of as taking a string date argument, and implicit arguments for the current workfile, and each observation in the workfile.
Since workfile functions are based on the structure of a workfile, they may only be used in operations where a workfile is involved. Workfile functions may be used in statements that generate series in a workfile, in statements that set the workfile sample, and in expressions used in estimating an equation using data in a workfile.
Observation Functions
@after Indicators for whether observation postdates a date.
@before Indicator for whether observation precedes a date.
@cellid Within cross-section identifier series for panel workfile observation.
@crossid Cross-section identifier series for panel workfile observation.
@date Date number of observation.
@daycount Number of days of week in observation.
@during Indicator of whether an observation is between two dates.
@event Event identifier for observation.
@enddate Last possible date of observation.
@holiday Holiday identifier for observation.
@holidayset Multiple holiday identifiers for observation.
@hour Hour of the day of the observation (integer).
@hourf Hour of the date of the observation (floating point)
@isperiod Is this the first observation matching the specified period.
@minute Minute of the hour of the observation.
@month Month of the year of the observation.
@obsid Sequential observation index for the observation.
@pageinidx Indicators for whether each observation in the workfile page is in an index.
@quarter Quarter of the year of the observation.
@seas Seasonal dummy variable.
@second Seconds of the minute of the observation.
@weekday Day of the week of the observation.
@year Year of the observation.
Utility Functions
@dtoo Observation number in the workfile associated with a date string.
@ispanel Is the current workfile page panel structured.
@obsrange Number of observations in the workfile page .
@obssmpl Number of observations in the workfile sample.
@otod Workfile observation to date string.
@otods Sample observation to date string.
@pagefreq Frequency specification for the workfile page .
@pageids Workfile page observation identifiers.
@pageidx Index vector of the specified observations.
@pagerange Range specification of active workfile page.
@pagesmpl Sample specification in active workfile page.
@pagesmplidx Index vector of observations in the current sample.
Rolling (Moving) Statistics
You may compute rolling (moving) statistics that compute summary statistics for a moving window of values in a series object, producing one value for each observation in the workfile. EViews offers functions for computing moving sums, averages, sums-of-squares, variances, standard deviations, minimums, maximums, medians, skewness, and kurtosis for single series, and correlations, covariances, and inner products between series.
The rolling statistics may be divided into two classes. The first set of rolling statistics, with names beginning with “@mov”, propagate missing values. The second set with names beginning with “@m” do not propagate missing values. This class of functions acts like basic summary statistics by removing NAs as necessary.
In general, rolling statistics in EViews are computed on a trailing basis so that a 5-period moving average for a given period is computed using the current and four lagged values of the data.
• If you wish to center a moving window computation, you may perform the calculation using a lead of the data. Thus, “@movav(y, 5)” is a 5-period trailing moving average, and “@movav(y(2), 5)” is a 5-period moving average centered around the contemporaneous value.
• Because of its relative importance, a special centered moving average function
@movavc is provided. Note that if the number of periods provided is even, the moving average produces a weighted moving average where the ends receive 0.5 weights.
Note that in contrast to the functions described in
“Basic Statistics”, computation of the rolling statistic values does not depend on the workfile sample so that sample gaps will not change the underlying computations and values. The workfile sample only comes into play when you assign the values of the function to a target series.
Basic Information
@mnas Trailing moving missing observations.
@mobs Trailing moving non-missing observations.
Rolling Statistics (Ignore NAs)
@mav Trailing moving averages (ignore NAs).
@mavc Centered moving averages (ignore NAs).
@mcor Trailing moving correlations (ignore NAs).
@mcov Trailing moving population covariance (no d.f. adjustment; ignore NAs).
@mcovp Trailing moving population covariance (no d.f. adjustment; ignore NAs).
@mcovs Trailing moving sample covariance (d.f. adjusted; ignore NAs).
@minner Trailing moving inner product of two series (ignore NAs).
@mkurt Trailing moving kurtosis (ignore NAs).
@mmax Trailing moving maximums (ignore NAs).
@mmedian Trailing moving median (ignore NAs).
@mmin Trailing moving minimums (ignore NAs).
@mnas Trailing moving missing observations.
@mobs Trailing moving non-missing observations.
@mskew Trailing moving skewness (ignore NAs).
@mstdev Trailing moving sample standard deviation (d.f. adjusted; ignore NAs).
@mstdevp Trailing moving population standard deviations (non-d.f. adjusted; ignore NAs).
@mstdevs Trailing moving sample standard deviations (d.f. adjusted; ignore NAs).
@msum Trailing moving sums (ignore NAs).
@msumsq Trailing moving sums of squares (ignore NAs).
@mvar Trailing moving population variances (non-d.f. adjusted; ignore NAs).
@mvarp Trailing moving population variances (non-d.f. adjusted; ignore NAs).
@mvars Trailing moving population variances (d.f. adjusted; ignore NAs).
Rolling Statistics (Propagate NAs)
@movav Trailing moving averages (propagate NAs).
@movavc Centered moving averages (propagate NAs).
@movcor Trailing moving population correlations (propagate NAs).
@movcov Trailing moving population covariance (no d.f. adjustment; propagate NAs).
@movcovp Trailing moving population covariance (no d.f. adjustment; propagate NAs).
@movcovs Trailing moving sample covariance (d.f. adjusted; propagate NAs).
@movinner Trailing moving inner product of two series (propagate NAs).
@movkurt Trailing moving kurtosis (propagate NAs).
@movmax Trailing moving maximums (propagate NAs).
@movmin Trailing moving minimums (propagate NAs).
@movskew Trailing moving skewness (propagate NAs).
@movstdev Trailing moving sample standard deviations (d.f. adjusted; propagate NAs).
@movstdevp Trailing moving population standard deviations (non-d.f. adjusted; propagate NAs).
@movstdevs Trailing moving sample standard deviations (d.f. adjusted; propagate NAs).
@movsum Trailing moving sums (propagate NAs).
@movsumsq Trailing moving sums of squares (propagate NAs).
@movvar Trailing moving population variances (non d.f. adjusted; propagate NAs).
@movvarp Trailing moving population variances (non-d.f. adjusted; propagate NAs).
@movvars Trailing moving sample variances (d.f. adjusted; propagate NAs).
Cumulative Statistics
EViews provides functions for cumulative statistics computed using series data from the beginning or end of a sample to the current observation.
The family of standard cumulatives includes familiar statistics such as means, medians, standard deviations, and variances, to minimums and maximums, quantiles, numbers of observations and missing values.
• The more commonly employed statistics that use data from the beginning of a sample to the current observation may be termed forward cumulative statistics. These functions are names of the form “@cum---”.
• The statistics using data from the current observation to the end of a sample are referred to as backward cumulative statistics. These functions have names of the form “@cumb---”.
Importantly, note that these forward and backward cumulative functions default to use all of the data in the workfile. You may provide an alternate sample specification as a double quoted last argument to the function. Observations that are not in the specified sample will not contribute to the cumulative statistics.
In addition to the standard cumulative functions, EViews provides functions for specialized computation of cumulative sums involving first differences of the series. There are three types of functions:
• The first type, with names beginning with “@cumd”, computes cumulative differences of the series, conditional on being above, below, or at a threshold. We may think of these partial sum processes as threshold cumulative differences.
• The second type, with names beginning with “@dcumd”, computes differences of the threshold cumulative difference series.
• The third type, with functions that produce cumulative within a year, or within calendar unit basis.
Forward Cumulatives
@cummax Cumulative maximums of a series.
@cummin Cumulative minimums of a series.
@cumnas Cumulative number of missing observations of a series.
@cumobs Cumulative number of (non-missing) observations of a series.
@cumprod Cumulative products of a series or the elements of a matrix.
@cumstdev Cumulative standard deviations (d.f. corrected) of a series.
@cumstdevp Cumulative standard deviations (non-d.f. corrected) of a series.
@cumstdevs Cumulative standard deviations (d.f. corrected) of a series.
@cumsum Cumulative sums of a series or the elements of a matrix.
@cumsumsq Cumulative sums-of-squares of a series.
@cumvar Cumulative variances (non-d.f. corrected) of a series.
@cumvarp Cumulative variances (non-d.f. corrected) of a series.
@cumvars Cumulative variances (d.f. corrected) of a series.
Backward Cumulatives
@cumbmax Backward cumulative maximums of a series.
@cumbmean Backward cumulative means of a series.
@cumbmin Backward cumulative medians of a series.
@cumbnas Backward cumulative number of missing observations of a series.
@cumbobs Backward cumulative number of (non-missing) observations of a series.
@cumbprod Backward cumulative products of a series.
@cumbstdev Backward cumulative standard deviations (d.f. corrected) of a series.
@cumbstdevp Backward cumulative standard deviations (non-d.f. corrected) of a series.
@cumbstdevs Backward cumulative standard deviations (d.f. corrected) of a series.
@cumbsum Backward cumulative sums of a series.
@cumbsumsq Backward cumulative sums-of-squares of a series.
@cumbvar Backward cumulative variances (non-d.f. corrected) of a series.
@cumbvarp Backward cumulative variances (non-d.f. corrected) of a series.
@cumbvars Backward cumulative variances (d.f. corrected) of a series.
Threshold Cumulative Differences
@cumdn Cumulative sum of negative (below threshold) changes in a series.
@cumdp Cumulative sum of positive (above threshold) changes in a series.
@cumdz Cumulative sum of zero (at threshold) changes in a series.
Differences of Threshold Cumulative Differences
@dcumdn Difference of cumulative sum of negative (below threshold) changes in a series.
@dcumdp Difference of cumulative sum of positive (above threshold) changes in a series.
@dcumdz Difference of cumulative sum of zero (at threshold) changes in a series.
Calendar Cumulatives
@ytd Within-year cumulative sum (year-to-date).
By-Group Statistics
EViews offers a set of by-group statistics which compute statistics for sub-groups of data in the workfile sample, and assign the relevant value to each observation. These by-group statistics may be used as part of any series expression to transform the raw series data into a summary series
The functions take a series expression arg1 for which we wish to compute group statistics and one or more series expressions arg2, defining the values over which we wish to compute the statistics. In the leading case, you will provide a single series expression containing a series or alpha whose values will define the category. More generally, you may provide several series expressions separated by commas (arg2, arg3, ...) whose joint values define the categories.
By default, EViews will use the workfile sample when computing the descriptive statistics. You may provide an optional sample expression or named sample to adjust the computation.
There are two related functions of note,
@groupid(arg1[, arg2, arg3, arg4, ..., argn, smpl]])
returns an integer indexing the group ID for each observation of the series or alpha expressions given by the arguments, and
@ngroups(arg1[, arg2, arg3, arg4, ..., argn, smpl])
returns a scalar indicating the number of groups (distinct values) for the series or alpha expressions defined by the arguments.
By-Group Statistics
@firstsby First non-missing value in a series for each specified group.
@kurtsby Kurtosis for each specified group.
@lastsby Last non-missing value in a series for each specified group.
@maxsby Maximum values in a series for each specified group.
@meansby Mean of observations in a series for each specified group.
@mediansby Medians for a series for each specified group.
@minsby Minimum values in a series for each specified group.
@nasby Number of missing observations in a series or alpha for each specified group.
@obsby Number of non-missing observations in a series or alpha, for each specified group.
@quantilesby Empirical quantiles of a series for each specified group.
@skewsby Skewness for a series for each specified group.
@stdevpsby Population standard deviations (d.f. corrected) for a series for each specified group.
@stdevs Sample standard deviation (d.f. adjusted).
@stdevsby Sample standard deviations (d.f. corrected) for a series for each specified group.
@stdevssby Sample standard deviations (d.f. corrected) for a series for each specified group.
@sumsby Sum of observations in a series for each specified group.
@sumsqsby Sum of squared observations in a series for each specified group.
@varpsby Population variances (non-d.f. corrected) of a series for each specified grou
p.
@varsby Sample variances (d.f. corrected) of a series for each specified group.
@varssby Sample variances (d.f. corrected) of a series for each specified group.
By-Row Statistics
EViews offers a set of statistics which compute summaries using data from all of the series in each row of a group object, and assign that value to the corresponding observation. These by-row statistics may be used as part of any series expression to extract a row summary series from the data in a group.
Note that you may obtain the number of elements in the group rows using the
@columns function or using the data member
groupname.
@count.
Group Row Statistics
@rfirst First non-missing value in rows of group.
@rifirst Indices of first non-missing value in rows of group.
@rilast Indices of last non-missing value in rows of group.
@rimax Indices of row maximums of group.
@rimin Indices of row minimums of group.
@rlast Last non-missing values in rows of group.
@rmax Row maximums of group.
@rmin Row minimums of group.
@rnas Number of missing observations in row of group.
@robs Row numbers of non-missing observations in group.
@rstdev Row sample (d.f. corrected) standard deviations of group.
@rstdevp Row population (non d.f. corrected) standard deviations of group.
@rstdevs Row sample (d.f. corrected) standard deviations of group.
@rsumsq Row sums of squares of group.
@rvalcount Number of matching values in rows of group.
@rvar Row population (non d.f. corrected) variances of group.
@rvarp Row population (non d.f. corrected) variances of group.
@rvars Row sample (d.f. corrected) standard deviations of group.
Matrix Functions
Matrix Utility
@capplyranks Reorder the rows of the matrix using a vector of ranks.
@columns Number of columns in matrix object or group.
@convert Converts series or group to a vector or matrix after removing NAs.
@eqna Test for equality of data objects, treating NAs and null strings as ordinary and not missing values.
@explode Square matrix from a sym matrix object.
@fill Vector initialized from a list of values.
@grid Vector containing equally spaced grid of values.
@hcat Vertically concatenate matrices.
@implode Creates sym from lower triangle of square matrix.
@implodeu Creates sym from upper triangle of square matrix.
@isna Test for missing values.
@lower Lowercase representation of a string, or lower triangular matrix of a matrix.
@mnrnd Matrix of normal random numbers.
@neqna Inequality test (NAs and blanks treated as values, not missing values).
@ones Matrix or vector of ones.
@range Vector of sequential integers.
@rapplyranks Reorder the columns of a matrix using a vector of ranks.
@resample Randomly draw from the rows of the matrix.
@rmvnorm Multivariate normal random draws.
@scale Scale rows or columns of matrix.
@seq Vector containing arithmetic sequence.
@seqm Vector containing geometric sequence.
@sfill Create a string vector from a list of strings.
@sort Sort elements of data object.
@unvec Unstack vector into a matrix.
@unvech Unstack vector into lower triangle of sym.
@uniquevals Vector or svector of unique values of object.
@upper Uppercase representation of a string; or upper triangular matrix of a matrix.
@vcat Vertically concatenate matrices.
@vec Vectorize (stack columns of) matrix.
@vech Vectorize (stack columns of) lower triangle of matrix.
@zeros Matrix or vector of zeros.
Matrix Algebra
@cond Condition number of square matrix or sym.
@det Determinant of matrix.
@eigenvectors Matrix whose columns contain the eigenvectors of a matrix.
@lu LU decomposition of a matrix.
@norm Norm of series or matrix object.
@outer Outer product of vectors or series.
@pinverse Moore-Penrose pseudo-inverse of matrix.
@svd Singular value decomposition (economy) of matrix.
@svdfull Singular value decomposition (full) of matrix.
@trace Computes the trace of a square matrix or sym.
@unvec Unstack vector into a matrix.
@unvech Unstack vector into lower triangle of sym.
@vec Vectorize (stack columns of) matrix.
@vech Vectorize (stack columns of) lower triangle of matrix.
Matrix Statistics
@columns Number of columns in matrix object or group.
@cor Correlation of two vectors or series, or between the columns of a matrix or series in a group.
@cov Covariance (non-d.f.corrected) of two vectors or series, or between the columns of a matrix or series in a group.
@covp Covariance (non-d.f. corrected) of two vectors or series, or between the columns of a matrix or series in a group.
@covs Covariance (d.f. corrected) of two vectors or series, or between the columns of a matrix or series in a group.
@first The first non-missing value in the vector or series.
@ifirst Index of the first non-missing value in the vector or series.
@ilast Index of the last non-missing value in the vector or series.
@imax Index of maximum value.
@imaxes Indices of maximum value (multiple).
@imin Index of minimum value.
@imins Indices of minimum value (multiple).
@last The last non-missing value in the vector or series.
@mae Mean of absolute error (difference) between series.
@mape Mean absolute percentage error (difference) between series.
@maxes Maximum values (multiple).
@mins Minimum values (multiple).
@mse Mean of square error (difference) between series.
@nas Number of missing observations.
@norm Norm of series or matrix object.
@obs Number of observations.
@regress Perform an OLS regression on the first column of a matrix versus the remaining columns.
@rmse Root of the mean of square error (difference) between series.
@smape Symmetric mean absolute percentage error (difference) between series.
@stdev Sample standard deviation (d.f. adjusted).
@stdevp Population standard deviation (no d.f. adjustment).
@stdevs Sample standard deviation (d.f. adjusted).
@stdize Standardized data (using sample standard deviation).
@stdizep Standardized data (using population standard deviation).
@sumsq Arithmetic sum of squares.
@theil Theil inequality coefficient (difference) between series.
@trendcoef Trend coefficient from detrending regression.
@uniquevals Vector or svector of unique values of object.
@var Population variance (no d.f. adjustment).
@varp Population variance (no d.f. adjustment).
@vars Sample variance (d.f. adjusted).
Matrix Column Statistics
@cfirst First non-missing value in each column of a matrix.
@cifirst Index of the first non-missing value in each column of a matrix.
@cilast Index of the last non-missing value in each column of a matrix.
@cimax Index of the maximal value in each column of a matrix.
@cimin Index of the maximal value in each column of a matrix.
@cintercept Intercept from a trend regression performed on each column of a matrix.
@clast Last non-missing value in each column of the matrix.
@cmax Maximal value in each column of a matrix.
@cmean Mean in each column of a matrix.
@cmedian Median of each column of a matrix.
@cmin Minimal value for each column of the matrix.
@cnas Number of NA values in each column of a matrix.
@cobs Number of non-NA values in each column of a matrix.
@cprod Product of elements in each column of a matrix.
@cstdev Sample standard deviation (d.f. corrected) of each column of a matrix.
@cstdevp Population standard deviation (non-d.f. corrected) of each column of a matrix.
@cstdevs Sample standard deviation (non-d.f. corrected) of each column of a matrix.
@csum Sum of the values in each column of a matrix.
@csumsq Sum of the squared values in each column of a matrix.
@ctrendcoef Slope from a trend regression on each column of a matrix.
@ctrmean Trimmed mean of each column of a matrix .
@cvar Population variance of each column of a matrix.
@cvarp Population variance of each column of a matrix.
@cvars Sample variance of each column of a matrix.
Matrix Element Functions
@ebtw Element by element test for whether values are between two other values.
@ediv Element by element division of two matrices.
@eeq Element by element equality comparison of two data objects.
@eeqna Element by element equality comparison of two data objects with NAs treated as ordinary value for comparison.
@ege Element by element tests for whether the elements in the data objects are greater than or equal to corresponding elements in another data object.
@egt Element by element tests for whether the elements in the data object strictly greater than corresponding elements in another data object.
@einv Element by element inverses of a matrix.
@ele Element by element tests for whether the elements in the data object are less than or equal to corresponding elements in another data object.
@elt Element by element tests for whether the elements in the data object are strictly less than corresponding elements in another data object.
@emax Element by element maximums of two conformable data objects.
@emin Element by element minimums of two conformable data objects.
@emult Element by element multiplication of two matrix objects.
@eneq Element by element inequality comparison of two data objects.
@eneqna Element by element inequality comparison of two data objects with NAs treated as ordinary value for comparison.
@epow Raises each element in a matrix to a power.
@erecode Element by element recode of data objects.
Matrix Transformation
Overall Transformation
@capplyranks Reorder the rows of the matrix using a vector of ranks.
@demean Compute deviations from the mean of the data object.
@detrend Compute deviations from the trend of the data object.
@dupselem Identifier for the observation within the set of duplicates.
@dupsid Identifier for the duplicates group for the observation.
@dupsobs Number of observations in the corresponding duplicates group.
@rapplyranks Reorder the columns of a matrix using a vector of ranks.
@resample Randomly draw from the rows of the matrix.
Transform By-Column
@colcumprod Cumulative products for each column of a matrix.
@colcumsum Cumulative sums for each column of a matrix.
@colpctiles Percentile values for each column of a matrix.
@colranks Ranks of each column of the matrix.
@colsort Sort each column of the matrix.
@colstdize Standardize each column using the sample (d.f. corrected) standard deviation.
@colstdizep Standardize each column using the population (non-d.f. corrected) standard deviation.
Transform By-Row
@rowranks Matrix where each row contains ranks of the column values.
@rowsort Matrix where each row contains sorted columns.
Support Functions
@dbname String containing the default database name.
@equaloption Equals-to option value provided in the exec or run commands.
@env Windows environment variable string.
@errorcount Number of errors encountered running a program.
@evpath Directory path of the EViews executable.
@getnextname String containing next available name in the workfile.
@hasoption Indicator for whether option is provided in the exec or run command.
@isobject Does object exist in active workfile page.
@isvalidgroup Does the string represent a valid EViews group or auto-series.
@isvalidname Indicator for whether string represents a valid name for an EViews object.
@lasterrnum Last error number generated by a previously issued command.
@lasterrstr Last error message generated by a previously issued command.
@linepath Location of the program file currently being executed.
@maxerrcount Maximum number of errors in a program before halting execution.
@option Option string provided in the
exec or
run command.
@runpath Location of the program currently being executed.
@temppath Directory path for EViews temporary files.
@toc Elapsed time (since timer reset) in seconds.
@uidialog Display a dialog with multiple controls.
@uiedit Display a dialog with an edit control.
@uilist Display a dialog with a listbox control.
@uimlist Display a dialog with a multiple-select listbox control.
@uiradio Display a dialog with radio buttons.
@verstr EViews product name string.
@wdir List of all files in a directory.
@wfattrnames String containing a list of attribute names in the workfile .
@wfattrvals String containing a list of attribute values in the workfile .
@wfpath String containing path of current workfile.
@wlookup String list formed from objects in a workfile or database matching a pattern.
@wquery String containing list of object attributes for objects matching a database query
@xgetstr String value from the external application.
@xgetnum Scalar numeric value from the external application.
@xputnames List of objects created in foreign application using XPUT.
@xtype Type of active external connection.
@xverstr External application version number as a string
@xvernum External application version number as a number